

Semantic standards have been with us since the birth of the web, when it became clear to inventors of the web like Tim Berners-Lee and many others that meaning could be systematically captured, organized, and exploited to do valuable tasks.
Since then, the idea of applying formal semantics to enterprise data has come and faded in many iterations. The vision of the semantic web, a machine readable way to describe the meaning of data, could not be realized without a modeling language to allow sharing of meaning and a way to represent the information being understood. The OWL standard was created for modeling of domain knowledge and the RDF standard was created to represent knowledge.
Some key implementations like RSS feeds made use of RDF. But the biggest victories that really showed the power of semantics, whether implemented with standards or not, happened in the search engines where increasingly large knowledge graphs began to show up. If you look up the Irish Traditional Musical band The Chieftains in Google, you will see a display of all past members. This is a perfect example of the type of information a knowledge graph can associate and display about a search term. For most bands that are popular, you will see similar graphs because the system captured the information and then put it into a knowledge graph so it could be retrieved at a later point.

The same thing happens when you ask Siri or Alexa questions. They are consulting knowledge graphs that are based on semantic technology. But for the rest of us the idea of using semantics in the enterprise pops up and then fades in many different eras. Why does it keep coming back? What makes it fade? Are we ready for that to change? Can semantics start really working to take BI and Data Science to the next level and not be the walking dead of the tech world?
In my view the answer is yes and the time is now for semantics to finally reach a state of sustained life so that it no longer needs to keep coming back in a zombie form.
Why Semantics Standards in the Enterprise Keep Coming Back to Life
Now, when you think about semantics, it’s a mistake to only think about the technical aspects of the metadata in a semantic web implementation. Semantics are really about creating a common understanding. Shared semantics are what makes BI successful. The most successful BI implementations have a data model that is well understood and on top of it, analytics or dashboards that are well delineated as well. I call this the data product and it has the general structure shown in this diagram:
The data product creates value and radiates power because it allows people quickly to see things the same way. This common understanding reduces inefficiency during analysis and decision making that leads to what I call the data brawl — arguments about what data means rather than what action to take.
But in the current world, unfortunately, most of the semantics are ad hoc. Semantics are essentially in the minds of the programmers and modelers shown in the following diagram from a recent paper I helped write for Cambridge Semantics Inc. Semantics become shared when they are documented or become part of tribal knowledge. In many advanced data warehouse implementations, you find solid data catalogs or inventories so that a newcomer can understand quickly what the data means. But because these don’t have a structure that is machine readable, they serve an educational or governance purpose, but don’t lead to higher forms of automation and analysis. Another way to say this is that there is a big difference between documenting semantics, and operationalizing them.
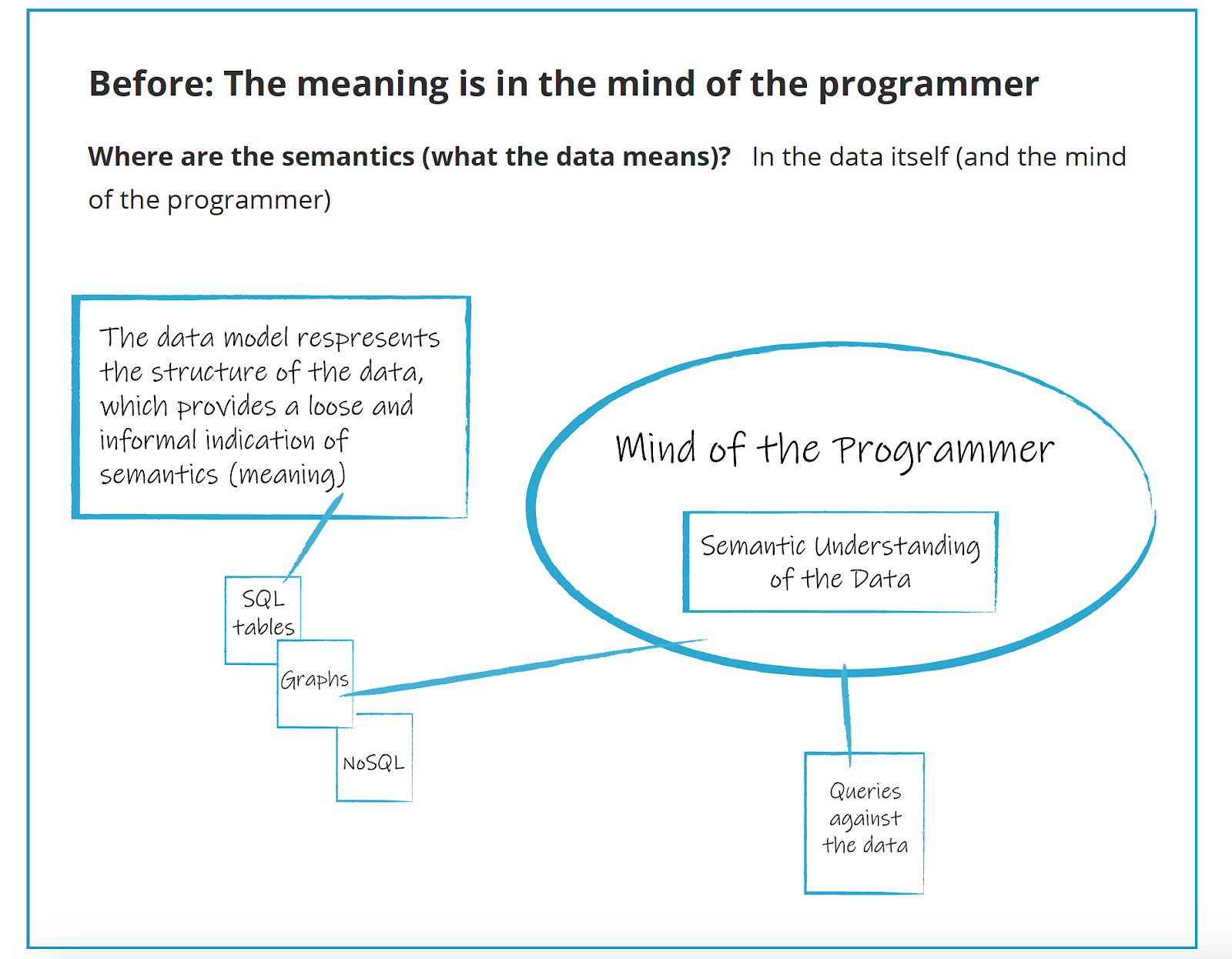
The problem with this is that semi-structured ways of keeping track of semantics means there’s no semantic wealth generated. There is no systematic way for machines or tools or people to keep track of this in a formalized way. That is the reason the semantic standards and semantic web have generated excitement is because they take those thoughts out of the minds of the programmers and modelers in a standardized way so that companies can keep track of a much larger semantic world with the assistance of machine learning, AI, algorithms, and other tools, as shown in this diagram:
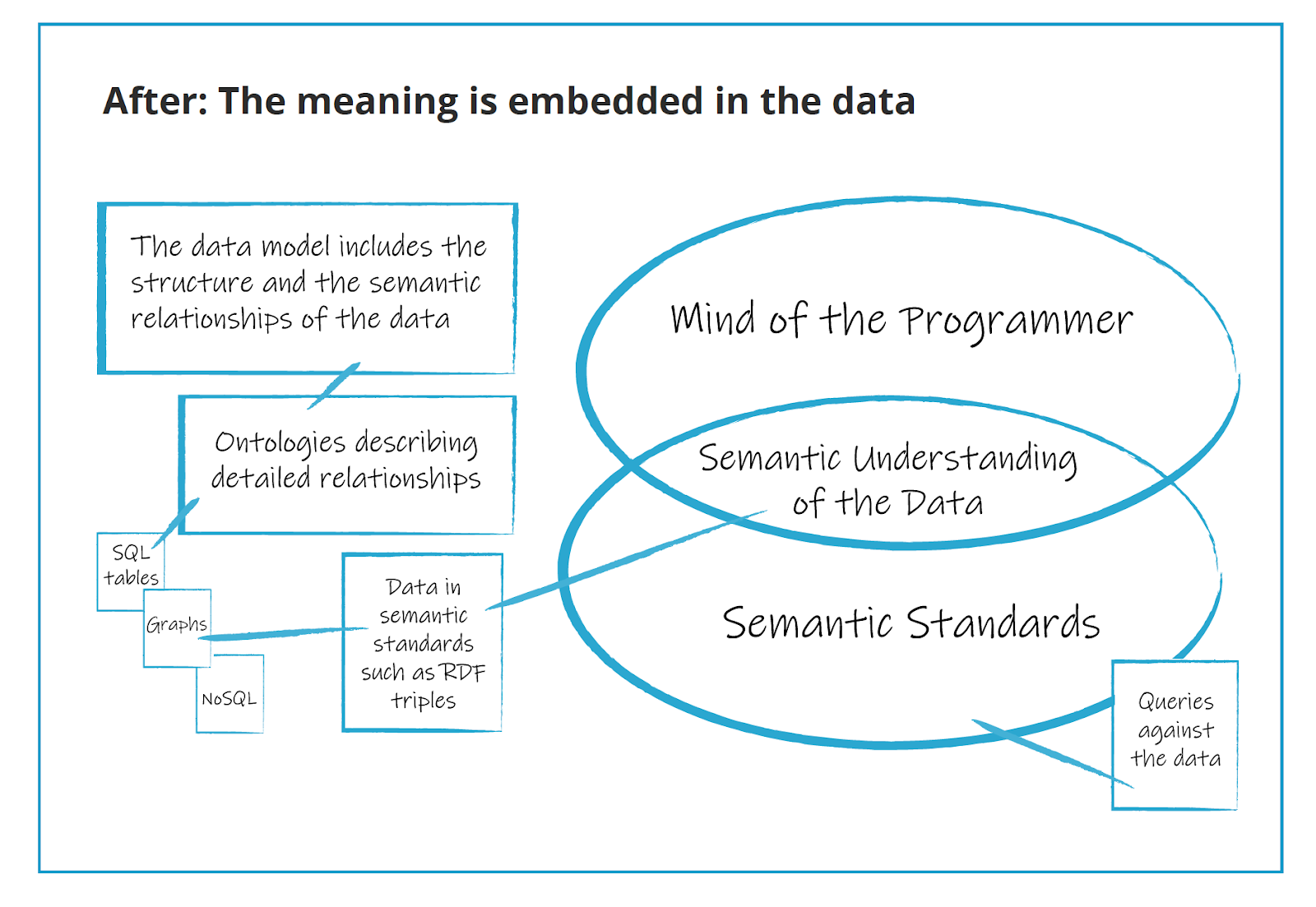
In short, they realize the semantics can be operationalized. The standards describe a repository for the semantic wealth of an organization. When you use a standard for encoding meaning like OWL to describe the labels available in a data set and storing them (also in RDF as a key to the meaning of the data they describe ) with the instance data in RDF, the meaning travels with the data and provides a way of preserving meaning of that data over time. It is a future proof data representation.
Software (like catalogs and searches) that operate against the OWL standard can help to make that data findable and far more easily reusable long into the future. Data thus described is immediately understandable by humans and by machines.
One property of the knowledge graph is that a huge variety of information can be represented in one form. For me one of the key insights is that in a knowledge graph, you ETL into labels not into tables, which you do with data warehouses. You have to do this with warehouses because you are morphing the data as you move it into ETL. Comparatively, a semantic web is essentially a graph of all of the labels applied to data connected together. Those labels can be used to make graphs that can be searched and explain deep relationships between data points, which creates a vision of all the data in your enterprise. Anyone with the slightest bit of imagination can see the power of such a knowledge graph and how it could create a much wider and deeper collection of information than we currently have.
Why Haven’t We Gotten There Collectively?
This vision of a comprehensive, ever expanding knowledge graph is what keeps semantics coming back to life. So why haven’t we got there? There are three primary reasons.
First, we lacked convenience at many different levels to build this type of semantic structure. The cost of building custom semantic web implementations was high and could only be justified by the highest value use cases.
Second, we lacked vision and support for a scalable architecture to work with the ever-changing nature of most businesses.
Third, we need a platform that productizes the ingestion of data into semantic form and the creation of knowledge graphs from it. Remember, to work at scale and avoid a huge maintenance burden, the connections of the knowledge graph must be based on the semantics, not on using brute force to make connections one at a time. Otherwise, the semantics will continue to live only in the minds of the programmers.
Now, the knowledge graphs that have succeeded so far have been built by brute force. All of the work just described (that is the knowledge graphs in Google or Siri) is done in code and with special purpose tools. For super high value use cases at companies with lots of engineering resources (like Google, Facebook, and LinkedIn), these knowledge graphs have succeeded. But semantics have faded away because the effort to create them and sustain them has been too high, not because the knowledge graphs are not valuable.
Are Semantics Ready to Come Alive?
I believe that semantics are ready to come alive now. Semantics can come to the enterprise if all the work mentioned above can become productized and convenient.
What do we need to make this possible? Here are the requirements for a productized platform that can really bring semantics to enterprise data in a useful form.
- It must be possible at scale to ETL into a set of labels that are managed as a coherent semantic system.
- We have to then be able to manage that growing semantic web of labels and be able to refactor that semantic system as needed and change the ETL to reflect it.
- From there, we must create layers of the web, just like we create layers of data models in BI as shown in the next diagram.

- Allow those layers to be refreshed from the landed data layer as needed.
- Ensure the connections in the knowledge graph are based on data not on semantics and direct connections.
- Then, by combining data from those layers, we can create many different forms of a working knowledge graph instead of just one graph as needed.
- Bring purpose built knowledge graphs to life in whatever deployment model makes sense, whether that is in the cloud, on premise, or on a device.
- We then need a way of exploring the graph and constructing queries in a guided fashion. Just putting a raw graph query language in front of people doesn’t solve the problem. We want to be able to explore all the advanced query mechanisms to explore these questions.
- Allow the space of all layers of the graph to be searched by data scientists.
- Permit various domains of graph to be searchable by various business users.
- Allow advanced algorithms and ML and AI methods to be applied to the knowledge graph in a guided manner as well.
- Deliver the output of the knowledge graph so that existing systems can consume it.
- Allow scale in breadth of volume of data.
- Allow fast query performance at scale.
- Make administration as easy as possible.
The more productized this stack becomes the more manageable it is, the more semantics will come to life and stop returning to the zombie state caused by frustrations and the effort to put semantics to work.